When evaluating the performance of the file systems we built, we concentrated on Wrapfs and the more complex file systems derived from Wrapfs: Cryptfs and Usenetfs. Since our file systems are based on several others, our measurements were aimed at identifying the overhead that each layer adds. The main goal was to prove that the overhead imposed by stacking is acceptably small and comparable to other stacking work[6,18].
We include comparisons to a native disk-based file system because disk hardware performance can be a significant factor. This number is the base to which other file systems compare to. We include figures for Wrapfs (our full-fledged stackable file system) and for lofs (the low-overhead simpler one), to be used as a base for evaluating the cost of stacking. When using lofs or Wrapfs, we mounted them over a local disk based file system.
To test Wrapfs, we used as our performance measure a full build of Am-utils[22], a new version of the Berkeley Amd automounter. The test auto-configures the package and then builds it. Only the sources for Am-utils and the binaries they create used the test file system; compiler tools were left outside. The configuration runs close to seven hundred small tests, many of which are small compilations and executions. The build phase compiles about 50,000 lines of C code in several dozen files and links eight binaries. The procedure contains both CPU and I/O bound operations as well as a variety of file system operations.
For each file system measured, we ran 12 successive builds on a quiet system, measured the elapsed times of each run, removed the first measure (cold cache) and averaged the remaining 11 measures. The results are summarized in Table 3.5 The standard deviation for the results reported in this section did not exceed 0.8% of the mean. Finally, there is no native lofs for FreeBSD, and the nullfs available is not fully functional (see Section 3.6).
First we evaluate the performance impact of stacking a file system. Lofs is 0.7-1.2% slower than the native disk based file system. Wrapfs adds an overhead of 4.7-6.8% for Solaris and Linux systems, but that is comparable to the 3-10% degradation previously reported for null-layer stackable file systems[6,18]. On FreeBSD, however, Wrapfs adds an overhead of 21.1% compared to FFS: to overcome limitations in nullfs, we used synchronous writes. Wrapfs is more costly than lofs because it stacks over every vnode and keeps its own copies of data, while lofs stacks only on directory vnodes, and passes all other vnode operations to the lower level verbatim.
Using the same tests we did for Wrapfs, we measured the performance of Cryptfs and CFS[2]. CFS is a user level NFS-based encryption file system. The results are also summarized in Table 3, for which the standard deviation did not exceed 0.8% of the mean.
Wrapfs is the baseline for evaluating the performance impact of the encryption algorithm. The only difference between Wrapfs and Cryptfs is that the latter encrypts and decrypts data and file names. The line marked as ``crypt-wrap'' in Table 3 shows that percentage difference between Cryptfs and Wrapfs for each platform. Cryptfs adds an overhead of 9.2-22.7% over Wrapfs. That significant overhead is unavoidable. It is the cost of the Blowfish cipher, which, while designed to be fast, is still CPU intensive.
Measuring the encryption overhead of CFS was more difficult. CFS is implemented as a user-level NFS file server, and we also ran it using Blowfish. We expected CFS to run slower due to the number of additional context switches that it incurs and due to NFS v.2 protocol overheads such as synchronous writes. CFS does not use the NFS server code of the given operating system; it serves user requests directly to the kernel. Since NFS server code is implemented in general inside the kernel, it means that the difference between CFS and NFS is not just due to encryption, but also due to context switches. The NFS server in Linux 2.0 is implemented at user-level, and is thus also affected by context switching overheads. If we ignore the implementation differences between CFS and Linux's NFS, and just compare their performance, we see that CFS is 3.2-8.7% slower than NFS on Linux. This is likely to be the overhead of the encryption in CFS. That overhead is somewhat smaller than the encryption overhead of Cryptfs because CFS is more optimized than our Cryptfs prototype: CFS precomputes large stream ciphers for its encrypted directories.
We performed microbenchmarks on the file systems listed in Table 3 (reading and writing small and large files). These tests isolate the performance differences for specific file system operations. They show that Cryptfs is anywhere from 43% to an order of magnitude faster than CFS. Since the encryption overhead is roughly 3.2-22.7%, we can assume that rest of the difference comes from the reduction in number of context switches. Details of these additional measurements are available elsewhere[24].
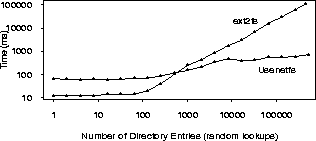
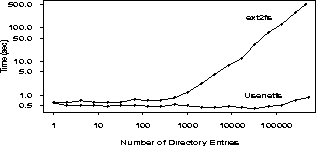
We configured a News server consisting of a Pentium-II 333Mhz, with 64MB of RAM, and a 4GB fast SCSI disk for the news spool. The machine ran Linux 2.0.34 with our Usenetfs. We created directories with exponentially increasing numbers of files in each: 1, 2, 4, etc. The largest directory had 524288 (219) files numbered starting with 1. Each file was 2048 bytes long. This size is the most common article size on our production news server. We created two hierarchies with increasing numbers of articles in different directories: one flat and one managed by Usenetfs.
We designed our next tests to match the two actions most commonly undertaken
by a news server (see Table 2). First,
a news server looks up and reads articles, mostly in response to users
reading news and when processing outgoing feeds. The more users there are,
the more random the article numbers read tend to be. While users read
articles in a mostly sequential order, the use of threaded newsreaders
results in more random reading.
The second common action a news server performs is creating new articles and deleting expired ones. New articles are created with monotonically increasing numbers. Expired articles are likely to have the smallest numbers so we made that assumption for the purpose of testing. Figure 6 (also log-log) shows the time it took to add 1000 new articles and then remove the 1000 oldest articles for successively increasing directory sizes. The results are more striking here: Usenetfs times are almost constant throughout, while adding and deleting files in flat directories took linearly increasing times.
Creating over 1000 additional directories adds overhead to file system
operations that need to read whole directories, especially the readdir call.
The last Usenetfs test takes into account all of the above factors, and was
performed on our departmental production news server. A simple yet
realistic measure of the overall performance of the system is to test how
much reserve capacity was left in the server. We tested that by running a
repeated set of compilations of a large package (Am-utils), timing how long
it took to complete each build. We measured the compile times of Am-utils,
once when the news server was running without Usenetfs management, and then
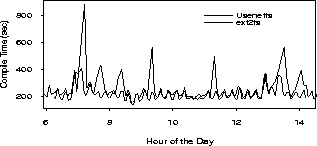
when Usenetfs managed the top 6 newsgroups. The results are depicted in
Figure 7. The average compile time was reduced by
22% from 243 seconds to 200 seconds. The largest savings appeared during
busy times when our server transferred outgoing articles to our upstream
feeds, and especially during the four daily expiration periods.
During these expiration peaks, performance improved by a factor of 2-3.
Lb2fs's performance is less than 5% slower than Wrapfs. The two main differences between Wrapfs and Lb2fs are the random selection algorithm and looking up directory vnodes on both replicas. The impact of the random selection algorithm is negligible, as it picks the least-significant bit of an internal system clock. The impact of looking up directory vnodes twice is bound by the ratio of directories to non-directories in common shared file systems. We performed tests at our department and found that the number of directories in such file systems to be 2-5% of the overall number of files. That explains the small degradation in performance of Lb2fs compared to Wrapfs.
We first developed Wrapfs and Cryptfs on Solaris 2.5.1. As seen in Table 4, it took us almost a year to fully develop Wrapfs and Cryptfs together for Solaris, during which time we had to overcome our lack of experience with Solaris kernel internals and the principles of stackable file systems. As we gained experience, the time to port the same file system to a new operating system grew significantly shorter. Developing these file systems for Linux 2.0 was a matter of days to a couple of weeks. This port would have been faster had it not been for Linux's different vnode interface.
|
The FreeBSD 3.0 port was even faster. This was due to many similarities between the vnode interfaces of Solaris and FreeBSD. We recently also completed these ports to the Linux 2.1 kernel. The Linux 2.1 vnode interface made significant changes to the 2.0 kernel, which is why we list it as another porting effort. We held off on this port until the kernel became more stable (only recently).
Another metric of the effort involved in porting Wrapfs is the size of the
code. Table 5 shows the total number of source lines for
Wrapfs, and breaks it down to three categories: common code that needs no
porting, code that is easy to port by simple inspection of system headers,
and code that is difficult to port. The hard-to-port code accounts for more
than two-thirds of the total and is the one involving the implementation of
each Vnode/VFS operation (operating system specific).
|
The difficulty of porting file systems written using Wrapfs depends on several factors. If plain C code is used in the Wrapfs API routines, the porting effort is minimal or none. Wrapfs, however, does not restrict the user from calling any in-kernel operating system specific function. Calling such functions complicates portability.