The design of Wrapfs concentrated on the following:
The first two points are discussed below. Performance is addressed in Section 5.
There are three parts of a file system that developers wish to manipulate: file data, file names, and file attributes. Of those, data and names are the most important and also the hardest to handle. File data is difficult to manipulate because there are many different functions that use them such as read and write, and the memory-mapping (MMAP) ones; various functions manipulate files of different sizes at different offsets. File names are complicated to use not just because many functions use them, but also because the directory reading function, readdir, is a restartable function.
We created four functions that Wrapfs developers can use. These four functions address the manipulation of file data and file names:
With the above functions available, file system developers that use Wrapfs as a template can implement most of the desired functionality of their file system in a few places and not have to worry about the rest.
File system developers may also manipulate file attributes such as ownership and modes. For example, a simple intrusion avoidance file system can prevent setting the setuid bit on any root-owned executables. Such a file system can declare certain important and seldom changing binaries (such as /bin/login) as immutable, to deny a potential attacker from replacing them with trojans, and may even require an authentication key to modify them. Inspecting or changing file attributes in Linux is easy, as they are trivially available by dereferencing the inode structure's fields. Therefore, we decided not to create a special API for manipulating attributes, so as not to hinder performance for something that is easily accessible.
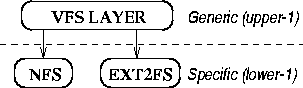
Without stackable file system support, the divisions between file system
specific code and the more general (upper) code are relatively clear, as
depicted in Figure 2.
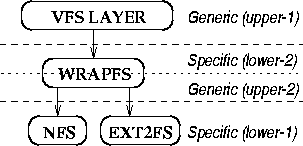
This dual role presents a serious challenge to the design of Wrapfs. The file system boundary as depicted in Figure 2 does not divide the file system code into two completely independent sections. A lot of state is exchanged and assumed by both the generic (upper) code and native (lower) file systems. These two parts must agree on who allocates and frees memory buffers, who creates and releases locks, who increases and decreases reference counts of various objects, and so on. This coordinated effort between the upper and lower halves of the file system must be perfectly maintained by Wrapfs in its interaction with them.
The Linux vnode interface contains several classes of functions:
Wrapfs was designed to accurately reproduce the aforementioned call sequence and existence checking of the various classes of file system functions.
There are five primary data structures that are used in Linux file systems:
The key point that enables stacking is that each of the major data
structures used in the file system contain a field into which file system
specific data can be stored. Wrapfs uses that private field to store
several pieces of information, especially a pointer to the corresponding
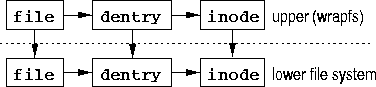
lower level file system's object. Figure 4 shows
Figure 4 also suggests one additional complication that Wrapfs must deal with carefully -- reference counts. Whenever more than one file system object refers to a single instance of another object, Linux employs a traditional reference counter in the referred-to object (possibly with a corresponding mutex lock variable to guarantee atomic updates to the reference counter). Within a single file system layer, each of the file, dentry, and inode objects for the same file will have a reference count of one. With Wrapfs in place, however, the dentry and inode objects of the lower level file system must have a reference count of two, since there are two distinct objects referring to each. These additional pointers between objects are ironically necessary to keep Wrapfs as independent from other layers as possible. The horizontal arrows in Figure 4 represent links that are part of the Linux file system interface and cannot be avoided. The vertical arrows represent those that are necessary for stacking. The higher reference counts ensure that the lower level file system and its objects could not disappear and leave Wrapfs's objects pointing to invalid objects.
Wrapfs keeps independent copies of its own data structures and objects. For example, each dentry contains the component name of the file it represents. (In an encryption file system, for example, the upper dentry will contain the cleartext name while the lower dentry contain the ciphertext name.) We pursued this independence and designed Wrapfs to be as separate as possible from the file system layers above and below it. This means that Wrapfs keeps its own copies of cached objects, reference counts, and memory mapped pages -- allocating and freeing these as necessary.
Such a design not only promotes greater independence, but also improves performance, as data is served off of a cache at the top of the stack. Cache incoherency could result if pages at different layers are modified independently[7]. We therefore decided that higher layers would be more authoritative. For example, when writing to disk, cached pages for the same file in Wrapfs overwrite their EXT2 counterparts. This policy correlates with the most common case of cache access, through the uppermost layer.